堆栈堆栈,「堆」和「栈」
经过无数技术书籍,以及各类技术博主苦口婆心的提醒,恐怕没几个人会再把堆和栈混为一谈,精明的开发者都明白,堆栈堆栈,「堆」和「栈」是不同的两种数据结构,具有各自的内存分配和使用方式。
众所周知,栈由编译器自动分配释放,堆由程序员手动分配释放,栈存放函数形参、局部变量,堆内存申请了记得释放……诸如此类,老生常谈。众所不周知,在不同的体系结构、裸机/操作系统下,堆栈在内存中的分配方式、内存布局、空间大小、存储内容也存在差异。
本文以 STM32 系列芯片(Cortex-M3 内核)和 RT-Thread 操作系统为例,梳理嵌入式开发过程中,与 MCU 堆栈有关的概念,然而堆栈涉及的知识太多,本文只侧重从内存分布角度阐述,帮助读者整体把握相关技术。
程序为什么需要堆栈
堆栈是程序访问内存的一种方式。
程序员在编程处理应用数据时,往往要使用大块连续的内存空间。程序指令在执行运算的过程中,也有大量中间结果需要临时保存,显然这些数据都是存放在内存当中,堆和栈便提供了这样一种机制:将内存分类管理,提供不同的访问方式。
堆和栈的使用更具体表现为,编程中使用的 malloc() 函数从堆内存分配空间,利用指针数组或内存函数使用。程序编译后所包含的大量 PUSH 和 POP 指令操作,系统根据 SP(堆栈指针) 寄存器访问当前对应栈内存,通过栈保存临时数据。堆和栈在内存中的具体位置,是接下面篇幅中讨论的重点。
当然,内存空间只是连续字节数据的抽象,本身并不区分堆和栈的概念,它做的只是存储和读写信息。因此,如何定义堆栈、初始化建立堆栈环境,在嵌入式软件运行前便显得尤为重要。这涉及到处理器提供的堆栈机制、操作系统内存管理和进程切换等方方面面。
程序内存布局
在芯片内部存储器中,包含了代码、数据、堆栈等信息,存放在 Flash 和 SRAM 当中,这里有必要说明一下众多内存类型的地址空间分布,其中包含我们的主角 —— 堆栈。倒也不复杂,只需要一张图就能表示清楚:
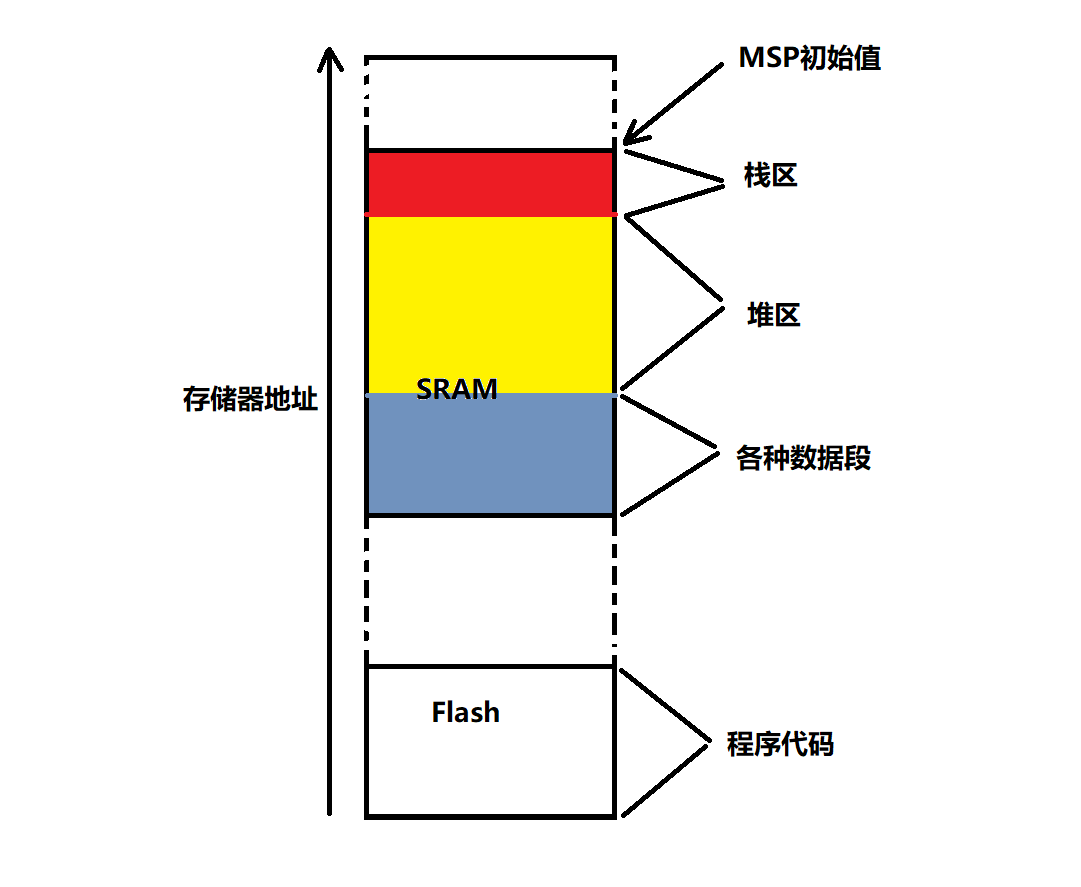
从图中可以看出,随着存储器地址的增长,依次对应 Flash 和 SRAM,Flash 中存放程序代码,SRAM 又可以分为数据区、堆区和栈区,接下来将详细介绍系统堆栈与内存布局之间的联系。
系统双堆栈机制
《Cortex-M3 权威指南》 12.1 节中,介绍了 M3 的双堆栈机制:
CM3 的出现,让单片机业界也能出双枪李向阳。 v7-M 架构的一个重要能力,就是提供了这个双堆栈的设计,允许把用户应用程序的堆栈与特权级/操作系统内核(kernel)的堆栈分开。如果再辅以 MPU,还能进一步地阻止用户程序访问内核的堆栈,同时也消除了内核数据被破坏的可能。
换句话说,在搭载实时操作系统内核的嵌入式软件中,栈往往分为两大类,除了满足系统基本的主栈(main stack)外,往往还需要进程/线程栈(process stack)。这两部分内存空间是独立存在的:主栈位于系统的栈区(stack),而线程堆栈往往定义在堆区(heap)或静态区(static),理解这一点,是理解 MCU 堆栈的关键前提。
查询寄存器定义得知,R13 为堆栈指针寄存器,底层实际分为 MSP 和 PSP —— 存放栈顶指针,分别对应主堆栈和线程堆栈,并且在同一时刻,只有其中的一个栈可用。在系统复位后、进入线程环境前,默认使用主堆栈,中断服务程序(ISR)中也是使用主堆栈。RTOS 各线程中的应用代码,则使用线程堆栈。
上电后,系统仅初始化了 MSP,需要通过额外的汇编代码建立完整的双堆栈系统,当实时内核准备就绪,线程调度正常运行,双堆栈机制开始工作。进中断时系统根据当前状态自动切换堆栈,进程上下文切换时会更新不同线程的 PSP,通过修改 EXC_RETURN(我也不知道是个啥)可以手动切换 MSP/PSP。
双堆栈机制使得内核/ISR 堆栈和线程应用堆栈分开管理,通过不同的堆栈指针寄存器完成切换,大大提高了系统的效率,在绝大部分的嵌入式实时操作系统中,都使用了双堆栈机制,如 ucos、FreeRTOS、RT-Thread 等。
注:在一些简单的应用中,例如裸机程序,可以从头到尾都只使用主堆栈,只要确保分配足够的空间即可。
主栈(main stack)
启动文件相关配置
主堆栈系统中最基本的栈,也是上电复位后默认使用的第一个栈。主栈在汇编启动文件中指定大小、分配空间:
; startup_stm32f405xx.s
...
Stack_Size EQU 0x00000400
AREA STACK, NOINIT, READWRITE, ALIGN=3
Stack_Mem SPACE Stack_Size
__initial_sp
...
上述代码中,使用 SPACE 汇编指示字,开出了 1024 字节的内存空间,起始地址为 Stack_Mem,结束地址为 __initial_sp。结束地址会作为栈顶,被定义在向量表前的零地址起始处,这是因为 CM3 复位序列规定,在离开复位状态后, CM3 做的第一件事就是从地址 0x00000000 处取出 MSP 的初始值:
; startup_stm32f405xx.s
...
__Vectors DCD __initial_sp ; Top of Stack
DCD Reset_Handler ; Reset Handler
DCD NMI_Handler ; NMI Handler
...
主栈位于栈区
关于 Stack_Mem 和 __initial_sp 两个符号的更多信息,可以从 Keil 工程的 map 文件中获取。以基于 stm32f401re、运行 RT-Thread 操作系统的工程为例,map 文件中 Local Symbols 符号表的结尾部分体现了以上符号的内存属性。
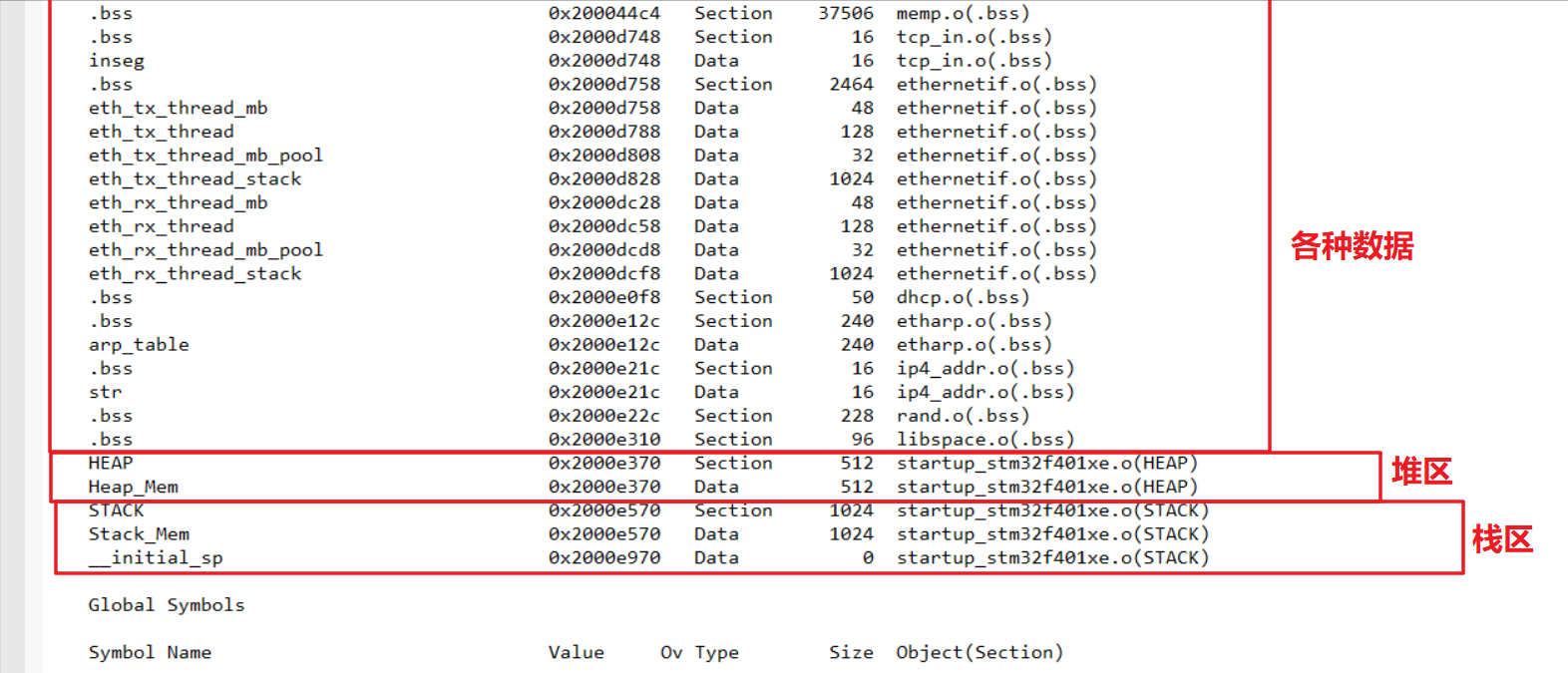
图中存储器地址从上往下递增,依次为数据、堆区和栈区,和前面「程序内存布局」一节中图片一致。一个非常重要的信息是:Stack_Mem 代表的主栈空间,位于系统的栈区,其起始地址紧接着堆区结尾,大小为 1024 字节(由启动文件的 Stack_Size 指定)。
经过上述分析可以得到结论:系统的栈区就是指主栈,大小由启动文件指定。
线程栈(process stack)
线程栈功能同主栈一样,在运行线程环境中代码时使用,在 RTOS 下开发应用程序需密切关注。
RT-Thread 中创建线程有两种方式,静态初始化和动态创建,分别对应 rt_thread_init()、rt_thread_create() 接口。这两个接口都要求调用者提供线程栈的信息,初始化线程需要提供静态内存空间(通常为全局数组形式)及线程栈大小,动态创建只需传入栈大小,由系统动态分配空间。
通过查看源码文件 thread.c 可以证实这一点:
// thread.c
rt_thread_t rt_thread_create(const char *name,
void (*entry)(void *parameter),
void *parameter,
rt_uint32_t stack_size,
rt_uint8_t priority,
rt_uint32_t tick)
{
struct rt_thread *thread;
void *stack_start;
thread = (struct rt_thread *)rt_object_allocate(RT_Object_Class_Thread,
name);
if (thread == RT_NULL)
return RT_NULL;
stack_start = (void *)RT_KERNEL_MALLOC(stack_size); // 动态分配线程栈空间
if (stack_start == RT_NULL)
{
/* allocate stack failure */
rt_object_delete((rt_object_t)thread);
return RT_NULL;
}
...
}
// rtdef.h
/* kernel malloc definitions */
#ifndef RT_KERNEL_MALLOC
#define RT_KERNEL_MALLOC(sz) rt_malloc(sz)
#endif
使用静态方式创建线程,线程栈内存由程序员提前准备,通常使用全局数组,此时线程栈内存位于数据段。若使用动态创建,线程栈在 rt_thread_create() 内部通过 malloc() 分配。这和普通应用程序申请内存一样,由操作系统内存管理算法在堆区分配。
无论是静态还是动态创建,线程栈都不会占用栈区的主栈空间。即线程栈并不在栈区,可能在数据区或堆区,再次说明主栈和线程栈内存空间独立。
栈内存分布与验证
为了进一步加深理解,考虑以下四种情况的堆栈内存分布:
- 裸机单堆栈(主栈)
- 两个动态线程的双堆栈系统
- 两个静态线程的双堆栈系统
- 一个静态一个动态线程的双堆栈系统
基于文章前半部分假设,主栈位于栈区,线程栈根据创建方式,分配在数据段或堆区。使用 Windows 自带灵魂画图工具,制作堆栈内存分布图示:
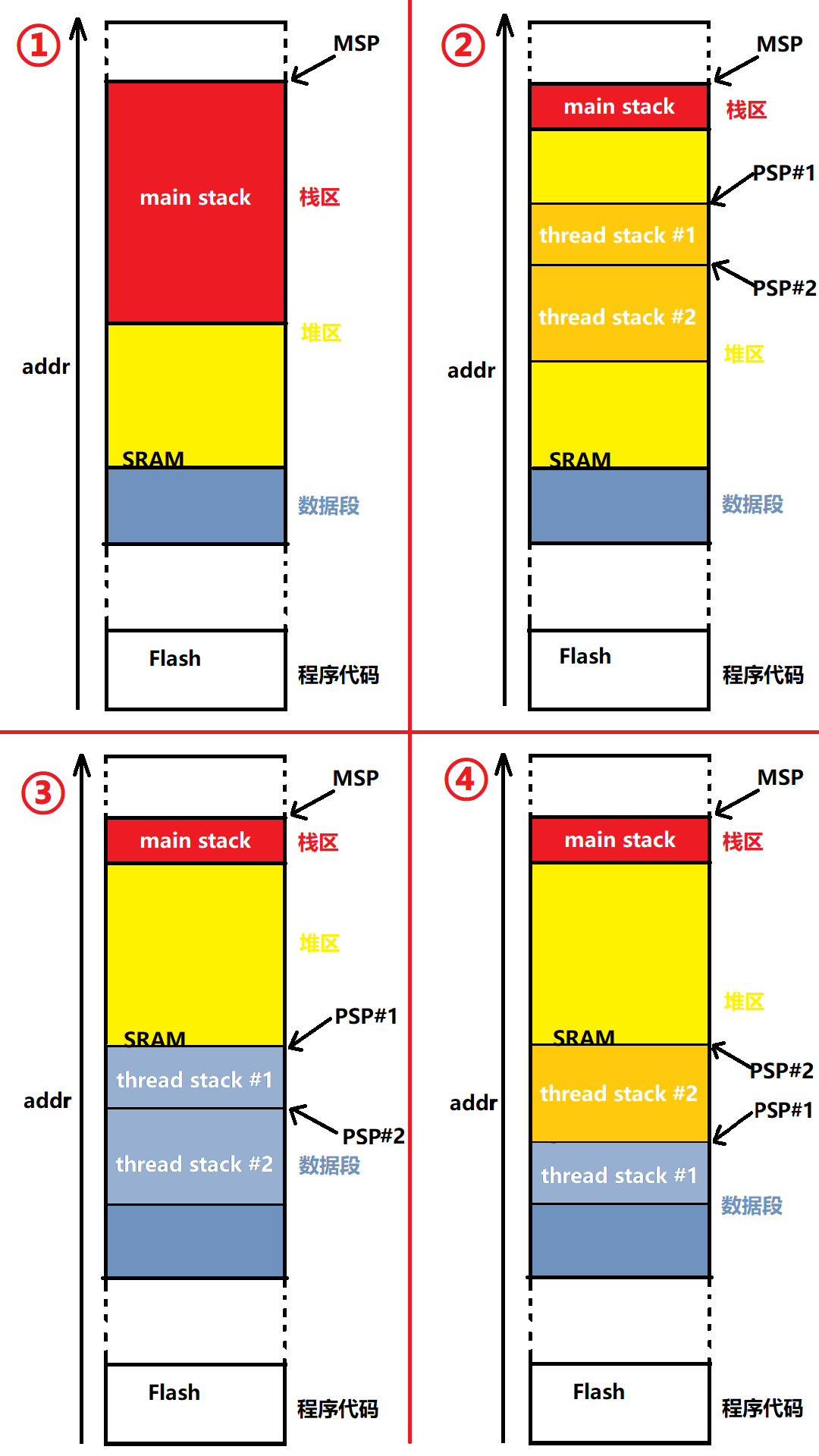
在使用动态创建线程的程序中,线程栈分配在堆区,使用一小段代码便能验证这一点:
int main(void)
{
int a = 1234;
rt_kprintf("&a = %p\r\n", &a);
rt_kprintf("HEAP_BEGIN: %p, HEAP_END: %p\r\n", HEAP_BEGIN, HEAP_END);
return RT_EOK;
}
目的在于对比局部变量 a 的地址(局部变量在栈内存分配)和堆区起始、结束地址(系统宏定义)大小关系,运行结果如下:
\ | /
- RT - Thread Operating System
/ | \ 4.0.1 build Mar 19 2020
2006 - 2019 Copyright by rt-thread team
lwIP-2.0.2 initialized!
[I/WLAN.dev] wlan init success
[I/WLAN.lwip] eth device init ok name:w0
[I/WLAN.dev] wlan init success
[I/WLAN.lwip] eth device init ok name:w1
rw007 sn: [rw0072795b244009948]
rw007 ver: [1.2.9-daeedc69-28654]
&a = 2000f1f8
HEAP_BEGIN: 2000e970, HEAP_END: 20018000
msh >
msh >
显然,a 的地址 2000f1f8 位于 HEAP_BEGIN 2000e970 和 HEAP_END 20018000 之间,证实了我们前面的结论。
总结
堆栈是程序运行的基础设施,按理说只要有一个够大的主栈,对裸机程序也足够了。操作系统本身作为一个特殊的「裸机程序」,为了实现多任务,也需要管理不同线程的栈内存。硬件平台提供的双堆栈支持,很大程度上就是在适应 OS 的实现,两者相辅相成,形成更高效可靠的嵌入式系统。
文章将近结尾,而关于双堆栈机制的讨论还有很多内容,包括 MSP、PSP 对应的系统状态和特权等级、不同栈指针的切换和栈溢出保护等等等等,相对于这些硬核知识,本文只是简单从内存分布角度,让读者对双堆栈机制有大体感性认识。
正所谓,抛砖引玉领进门,修行还得靠个人。
参考资料
